John F. Sowa
John Sowa is an American computer scientist, an expert in artificial intelligence and computer design, and the inventor of conceptual graphs. Over the past several years he has been developing a series of slides to overview key problems and challenges relating to the current state of language understanding by computer. You can download The Goal of Language Understanding (November 15, 2013 version) here. The following topics are from the summary.
1. Problems and Challenges
Early hopes for artificial intelligence have not been realized. The task of understanding language as well as people do has proved to be far more difficult than anyone had thought. Research in all areas of cognitive science has uncovered more complexities in language than current theories can explain.A three-year-old child is better able to understand and generate language than any current computer system.
Questions:
- Have we been using the right theories, tools, and techniques?
- Why haven’t these tools worked as well as we had hoped?
- What other methods might be more promising?
- What can research in neuroscience and psycholinguistics tell us?
- Can it suggest better ways of designing intelligent systems?
2. Psycholinguistics and Neuroscience
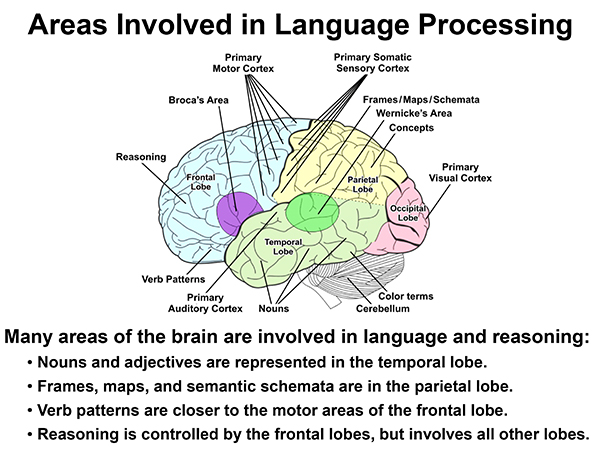
Brain areas involved in language processing
Language is a late development in evolutionary time. Systems of perception and action were highly developed long before some early hominin began to talk. People and higher mammals use the mechanisms of perception and action as the basis for mental models and reasoning. Language understanding and generation use those mechanisms.
Logic and mathematics are based on abstractions from language that use the same systems of perception and action. Language can express logic, but it does not depend on logic. Language is situated, embodied, distributed, and dynamic.
3. Semantics of Natural Languages
Human language is based on the way people think about everything they see, hear, feel, and do. And thinking is intimately integrated with perception and action. The semantics and pragmatics of a language are:
- Situated in time and space,
- Distributed in the brains of every speaker of the language,
- Dynamically generated and interpreted in terms of a constantly developing and changing context,
- Embodied and supported by the sensory and motor organs.
These points summarize current views by psycholinguists. Philosophers and logicians have debated other issues: e.g., NL as a formal logic; a sharp dichotomy between NL and logic; a continuum between NL and logic.
4. Ludwig Wittgenstein
Considered one of the greatest philosophers of the 20th century. Wrote his first book under the influence of Frege and Russell. That book had an enormous influence on analytic philosophy, formal ontology, and formal semantics of natural languages.
But Wittgenstein retired from philosophy to teach elementary school in an Austrian mountain village. In 1929, Russell and others persuaded him to return to Cambridge University, where he taught philosophy. During the 1930s, he began to rethink and criticize the foundations of his earlier book, including many ideas he had adopted from Frege and Russell.
5. Dynamics of Language and Reasoning
Natural languages adapt to the ever-changing phenomena of the world, the progress in science, and the social interactions of life.No computer system is as flexible as a human being in learning and responding to the dynamic aspects of language.
Three strategies for natural language processing (NLP):
- Neat: Define formal grammars with model-theoretic semantics that treat NL as a version of logic. Wittgenstein pioneered this strategy in his first book and became the sharpest critic of its limitations.
- Scruffy: Use heuristics to implement practical applications. Schank was the strongest proponent of this approach in the 1970s and ’80s.
- Mixed: Develop a framework that can use a mixture of neat and scruffy methods for specific applications.
NLP requires a dynamic foundation that can efficiently relate and integrate a wide range of neat, scruffy, and mixed methods.
6. Analogy and Case-Based Reasoning
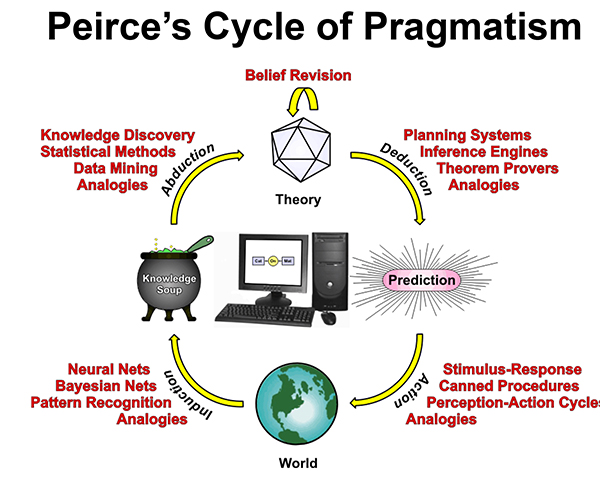
Induction, Abduction, Deduction, and Action
Based on the same kind of pattern matching as perception:
- Associative retrieval by matching patterns.
- Approximate pattern matching for analogies and metaphors.
- Precise pattern matching for logic and mathematics.
Analogies can support informal, case-based reasoning:
- Long-term memory can store large numbers of previous experiences.
- Any new case can be matched to similar cases in long-term memory.
- Close matches are ranked by a measure of semantic distance.
Formal reasoning is based on a disciplined use of analogy:
- Induction: Generalize multiple cases to create rules or axioms.
- Deduction: Match (unify) a new case with part of some rule or axiom.
- Abduction: Form a hypothesis based on aspects of similar cases.
7. Learning by Reading
Perfect understanding of natural language is an elusive goal:
- Even native speakers don’t understand every text in their language.
- Without human bodies and feelings, computer models will always be imperfect approximations to human thought.
For technical subjects, computer models can be quite good:
- Subjects that are already formalized, such as mathematics and computer programs, are ideal for computer sytems.
- Physics is harder, because the applications require visualization.
- Poetry and jokes are the hardest to understand.
But NLP systems can learn background knowledge by reading:
- Start with a small, underspecified ontology of the subject.
- Use some lexical semantics, especially for the verbs.
- Read texts to improve the ontology and the lexical semantics.
- The primary role for human tutors is to detect and correct errors.
The Process of Language Understanding
People relate patterns in language to patterns in mental models. Simulating exactly what people do is impossible today:
- Nobody knows the details of how the brain works.
- Even with a good theory of the brain, the total amount of detail would overwhelm the fastest supercomputers.
- A faithful simulation would also require a detailed model of the body with all its mechanisms of perception, feelings, and action.
But efficient approximations to human patterns are possible:
- Graphs can specify good approximations to continuous models.
- They can serve as the logical notation for a dynamic model theory.
- And they can support a high-speed associative memory.
This engineering approach is influenced by, but is not identical to the cognitive organization and processing in the human brain.