Anything we can do to improve our knowledge of our immediate physical, cognitive, social, and informational context, our personal state, threat awareness, and opportunity awareness, without unduly complicating matters — Clark Dodsworth.

Clark Dodsworth
Clark Dodsworth is a product strategist for next wave smart devices. According to Clark, any product is a tool, any tool is an interface: whether it’s software or hardware,… whether it involves interaction design, industrial design, visual design, public-space design, design management, or all of them. A tool should fit the user. A tool should adapt to the user.
Clark works with companies to improve tools, evolve tools, add and revise features of them, position them in the marketplace, and find the sweet spot for IP to become new tools.
Context is king
In 2010, Clark presented at the Augmented Reality Event in Santa Clara, CA. His topic was Context is King — AR, Salience, and the Constant Next Scenario. Highlights from this talk follow.

Eight layers of context awareness
Context is the interrelated conditions in which something exists or occurs (Merriam Webster). It is the situation within which something exists or happens and that can help explain it (Cambridge Dictionary). It is any information that can be used to characterize the situation of an entity (Dey, 1999). It is the set of environmental states and settings that either determines an application’s behavior or in which and application event occurs and is interesting to the user (Chen, Kotz 2000).
This diagram (above) depicts eight categories of context for smart services. Context-aware applications look at the who, where, what, and when of entities to determine why and how a situation is occurring.
What happens when there’s a software layer that learns you?

Augmented reality to cope with your constant next scenario
Augmented reality (AR) on smartphones, tablets and other platforms is a new and highly malleable set of tools and substrates for them. It is the path to how we can manage our daily work and life in the midst of the tsunami of of information we can get all the time, not to mention the daily social contacts we manage and deal with. The next steps for AR are about helping each user with the constant next scenario in their day, minute by minute…anticipating and supporting their process, without interrupting it. While we’ll get there step-by-step, we need to have this goal in mind, or we will undershoot the opportunity and delay very real efficiencies in our daily lives and work.
The preceding diagram is a data flow concept model of the information you generate as you proceed through your day, as well as the informational data you normally receive (text, voice, email, alerts, etc.), and how those streams should be processed by the three segments of hypersonalization services (App, OS, and Cloud).
Also, it shows the step of selecting the available sensory modes for delivery, which includes dynamically formatting the information for display in whichever mode is most appropriate.
It also indicates that device sensors will tend to be in constant contact with either cloud-based sensor datastreams or peer-to-peer ac-hoc (mesh) sensor nets, or both, to adequately inform you of relevant changes and states of your physical environment. They will not only receive but also contribute to both, in part as a way to pay for access to the aggregate sensor data feeds.
Once these three methods of analytics (salience, live context, and the actual decision-path, have learned enough about you, they begin to do probabilistic data staging and delivery for your next decision(s).
Augmented Context + Information Salience = Value.
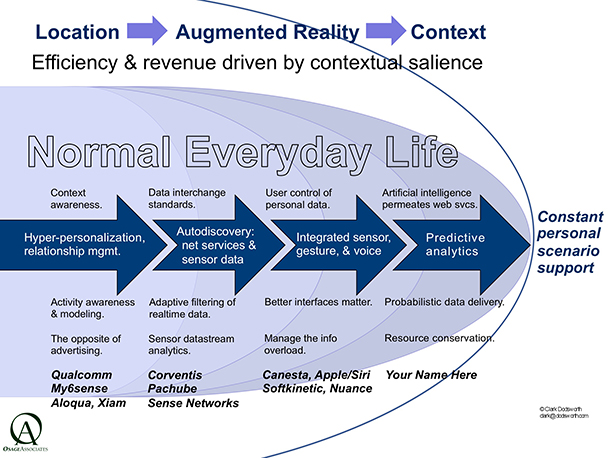
Constantly supporting the next scenario of my daily life
Augmented reality means dynamic, context-driven hyperpersonalization, salience filtering, & scenario modeling in order to adaptively deliver info, highly personalized via N-dimensions of user states, with high space/time precision, and without spiking your cognitive load. There is constant auto discovery of data feeds and sensor feeds. There is constant markerless 2D & 3D feature identification and object recognition linked to motion analysis and evaluation. There is indoor position mapping seamlessly linked with outdoor GPS position sensing. There is nuanced gestural and integration with voice as well as constant audio + visual awareness.
Allostatic control delivers only the data needed, when needed. “Allostasis” is maintenance of control through constant change. This means avoiding user distraction by constantly contextually evaluating what should be displayed to the user, if anything. Without sophisticated software “awareness” to drive what information is inserted into the user’s awareness, we quickly hit the complexity wall. Providing the right amount of information we need, when we need it, and only the amount we need, in the sensory mode that’s most appropriate at the moment, is the doable goal.
Smart tools fit the user and the task. They adapt to — i.e. learn — the user over time, becoming more useful to the individual the more they’re used. Good augmented reality tools adapt dynamically. Otherwise ongoing management of their services is too distracting. Smart tools must provide their value to us without the amount of user configuring we’ve become accustomed to.
When systems record, analyze, and thus learn from user choices over time, they learn what scenarios you select at each moment. They can then begin to provide information services for the next impending choice situation – a set of scenarios you’ll choose from that may need information-services support. Every day.
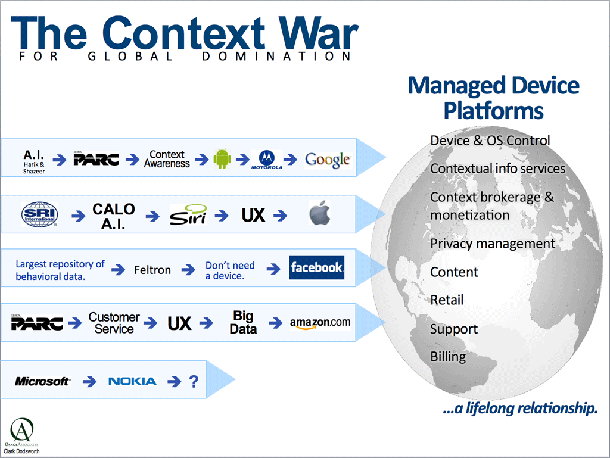
The Context War
Information vendors and access providers can create new revenue streams by becoming trusted, high-security vendors of tracking and analysis of user’s paths through location, time, people, tasks, decisions, interests, alerts, ads, priorities, and the publicly shared priorities of his/her friends and associates. Providing a set of analytical services that can be selected and turned on and off by the user, and whose value accretes over time, will become viewed as the most effective way for individuals to parse the information they need to use in their day-to-day work and life. This is closely related to just-in-time learning, and constant on-the-job training, and life-long learning.
Smart systems and devices, context-aware computing, and augmented reality define the next battle field for managed device platforms. It’s all about long-term, sustaining, contextually dynamic, hyper-personalized relationships between users and networked delivered services. As shown in the following diagram, five vendor camps have formed along lines of research and are competing to create the dominant smart platform ecosystem. Contending camps include: Google (Android), Apple (iOS), Facebook, Amazon, and Microsoft.
Thanks Clark.